What is the goal of this project?
The goal of the contest is to predict the sale price of a particular piece of heavy equipment at auction based on its usage, equipment type, and configuration. The data is sourced from auction result postings and includes information on usage and equipment configurations.
Context
This was the first case study I worked on at Galvanize. I was on a team of three and my primary role was to write the code that used the averaged of previous prices to predict an item's auction price.
What tools did I use?
I analyzed the data with python using pandas, numpy, and sklearn.
What was the big takeaway?
Often the simplest model is the best, and a little insight can go a long way.

Step 0: The Background Stuff
I wouldn't want to lose your interest with background imports and functions, but you can head over here (hyperlink forthcoming) for more details.
Step 1: Get Average Sale Price By Model
Here's where things get interesting! Most groups built models based on features such as the item's age or engine size. But we reasoned that the best predictor of price would be the price the same item sold for at previous auctions. So if I wanted to know the price of a pinecone, it would be helpful to know that two previous pinecones sold for $4 and $5.
To implement this strategy, I create a new table that is indexed by model id and has columns of "SalePrice", "Counts", and "AvgPrice".
I can then use this table to look up the average sale price by model id.
train_df['Counts'] = 1
avg_prices_df = train_df[['ModelID','SalePrice','Counts']].groupby('ModelID').sum()
avg_prices_df['AvgPrice'] = (avg_prices_df.SalePrice / avg_prices_df.Counts).round(2)
avg_prices_df.head()
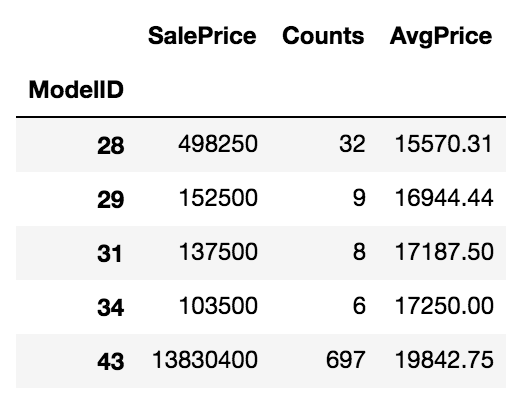
Quick interpretation: The first row shows that if we consider items with a model id of "28", thirty two were sold with total sales of $498,250, or about $15,570 per item. So if I were to predict the price of another item with a model id of 28, $15,570 is not a bad guess.
Step 2: Create A Function That Predicts Sale Price By Simple Lookup
In order to make predictions, we need a function that looks up the predicted price. Just in case an unseen item shows up in the test set, we also need to calculate the average price accross all items.
(Would it be interesting to turn this into a dictionary to speed lookup time?).
def predict_price(id):
try: return avg_prices_df.loc[id]['AvgPrice']
except: return avg_sale_price
avg_sale_price = train_df.SalePrice.sum()/len(train_df)
Step 3: Use The Function To Predict Prices in the Test Data
The final step - use the "predict prices" function to predict prices of unseen data, and score that model with the actual prices.
test_predicted_prices = test_df.ModelID.apply(predict_price)
score_gtap = score(test_predicted_prices, test_actual_prices)
print("The guess-the-average-price model has a RMLSE of {:.4}.".format(score_gtap))
This model earned a RMLSE of 0.3209. For comparison, the next lowest score was around .6, nearly twice my result. Hurrah!
Unfortuantely, this solution wasn't strictly legal. By the terms of the competition, we were required to create a linear model. Luckily, this wasn't hard to do once I had the average price lookup table and function. In essence, we created another feature that was the "average price of that model" and then fit a linear model with that feature. Unsurprisingly, the model almost entirely ignored the other features and made its prediction with just that one column.
At first I thought it was arbitrary that I had to contort my solution to work within the constraints. If I could do it better with a simple lookup, why go any further? Now, however, I have two reasons why being able to reformat my solution to work as a linear regression is potentially useful.
The first is that my results may be just a piece of a larger pipeline. Perhaps someone downstream of me has code that only works when a model is sent its way, and wouldn't know what to do with a function.
The second reason is that formating my results as a linear model gives me the flexibility to consider other features, such as the age of the equiptment. Afterall, there is a wide range of prices for any particular model. In the time given we weren't able to make use of other features such as equiptment age, but in the future that could be a very rich avenue of study.
Summary
I was really proud that my method did so well, although I did find it odd that I didn't actually use linear regression.
When I talked to other people in the data sciency industry about this project, they said my situation wasn't uncommon. Sometimes the simplest models work best, and I learned that I should be wary of throwing data at an advanced model without thinking through the real effects under the surface.